Impala Architecture
Table of Contents
- Impala Daemon
- Query Planner
- Query Coordinator
- Query Executor
- C++, Data Alignment, SIMD instructions
- Code generation & LLVM
- Performance Profiling
- Statestore Service
- Catalog Service
- Conclusion
This chapter covers
- Impala’s distributed architecture
- Impalad’s Query Planner, Coordinator, and Executor
- Statestore and catalog services
- Optimization of SQL queries
- Performance profiling for query execution and bottlenecks
Previous chapters described Impala’s SQL query language, and you learned to query data distributed over the cluster. This chapter will shed a light on how your query is executed and how the results are collected from the different nodes. Knowing the distributed architecture not only helps you understand what makes Impala fast, but it also helps you improve the performance of your queries, because it allows you to identify bottlenecks in the query’s execution path.
This chapter covers Impala’s three main services:
- Impalad: This daemon, at the heart of Impala, is deployed on every node of the cluster. When a client sends an SQL query to a random node, the node becomes the coordinating node. This node becomes responsible for executing the query, collecting the partial results, and sending the aggregated results back to the client. It is the impalad daemon that processes the query.
- Statestore service: This component monitors the health of the Impala cluster. The health information is distributed back to all the Impala daemons. If a node fails for whatever reason, the other daemons will be informed and the dead node will be avoided in future queries.
- Catalog service: This service takes care of distributing any change in the metadata to all daemons. Any update on the database, such as adding a column to a table, is dispersed to every node. The chapter finishes with an explanation of a performance profile. A performance profile is created by number of tools that give a comprehensive overview of how the query is executed and where the bottlenecks are. The profile will make a lot more sense once you understand the different services. At the end of the chapter, you’ll be able to identify and avoid possible bottlenecks of the query’s execution path and make them perform faster.
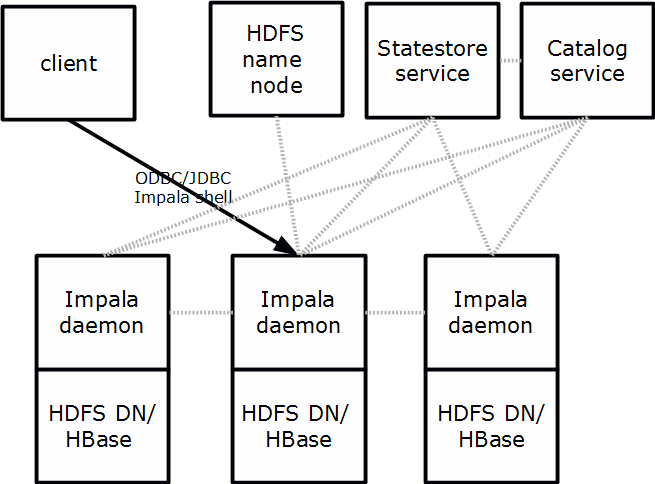 Figure 1 Overview of the different services used in Impala
Figure 1 Overview of the different services used in Impala
At the upper right of the figure, there are single instances of the Statestore and Catalog service. Impala works closely with the HDFS Name node to locate the individual data blocks. An Impala daemon (shown in the middle of the figure) runs on every data node in the cluster that will access the local data. Each daemon communicates not only with the statestore and the catalog service, but also with other daemons.
Throughout this chapter, we’ll illustrate the transformation, optimization and execution of a query based on a running example. The example retrieves the top 10 most active countries on the NASA web site.
NASA Dataset This chapter’s examples are based on the NASA dataset we first introduced in Chapter 3. To make the profiling more explicit, three new tables have been added:
- The first table contains the NASA web logs,
- the second table contains a mapping from the host name to a country code, and
- the third table contains a mapping from country code to country name. The tables are tuned for educational purposes, not for a production environment.
The following three listings give more details of the tables used in the example. Listing 1 below shows the columns of the additional tables.
Listing 1 Additional tables for Nasa dataset
[localhost.domain:21000] > describe geoip;Query: describe geoip
+--------------+--------+---------+
| name | type | comment |
+--------------+--------+---------+
| host | string | | #A
| ip | string | |
| city | string | |
| lat | float | |
| lon | float | |
| country_code | string | |
+--------------+--------+---------+
[localhost.domain:21000] > describe country;
Query: describe country
+------+--------+---------+
| name | type | comment |
+------+--------+---------+
| code | string | | #B
| name | string | |
+------+--------+---------+
#A The table geoip associates a host to a geolocation, such as lon/lat and country code
#B The table country contain the country code and country name
In the next listing, we query the size of every table. The NASA weblog table is by far the largest. The table country contains only 86 rows. In section 1.1, we will explain the importance of the size of each table.
Listing 7.2 Size of each table in the dataset
[localhost.domain:21000] > select count(*) from weblog; #A
Query: select count(*) from weblog
+----------+
| count(*) |
+----------+
| 1891715 |
+----------+
[localhost.domain:21000] > select count(*) from geoip; #B
Query: select count(*) from geoip
+----------+
| count(*) |
+----------+
| 365912 |
+----------+
[localhost.domain:21000] > select count(*) from countries;
Query: select count(*) from countries
+----------+
| count(*) |
+----------+
| 86 |
+----------+
Listing 3 describes the query we’ll use throughout the chapter. The query combines the three tables to retrieve the top 10 consumers of valid requests per country:
- For each valid web log (valid means the reply code is 200 and the host is populated), the geoip information is retrieved.
- The geoip information gives us the longitude, latitude and country code for the host of the weblog.
- Using the country code, the country name is retrieved from the country table.
- For each country, the total amount of each weblog reply is calculated and sorted.
- Only the top 10 results are returned.
Listing 3 Return the top 10 countries that visit the NASA web site
SELECT country.name, SUM(weblog.bytes) as total #A
FROM country #B
INNER JOIN geoip ON country.id = geoip.country_id #B
INNER JOIN weblog ON geoip.host = weblog.host #B
WHERE weblog.reply = "200" and weblog.host is not null #C
GROUP BY country.name #D
ORDER BY total #E
LIMIT 10 #F
#A Query the total amount of bytes for each country
#B The query joins the tables: a weblog.host maps to a geoip.host which maps to a country.name
#C Only consider valid replies and only consider logs with a valid host
#D The aggregation level is country
#E Return only the top 10 largest
The Impala daemon is the component where all the action takes place. Within impalad (the technical name for Impala daemon), there are 3 layers, as shown below in figure 2: Query Planner, Query Coordinator, and Query Executor.
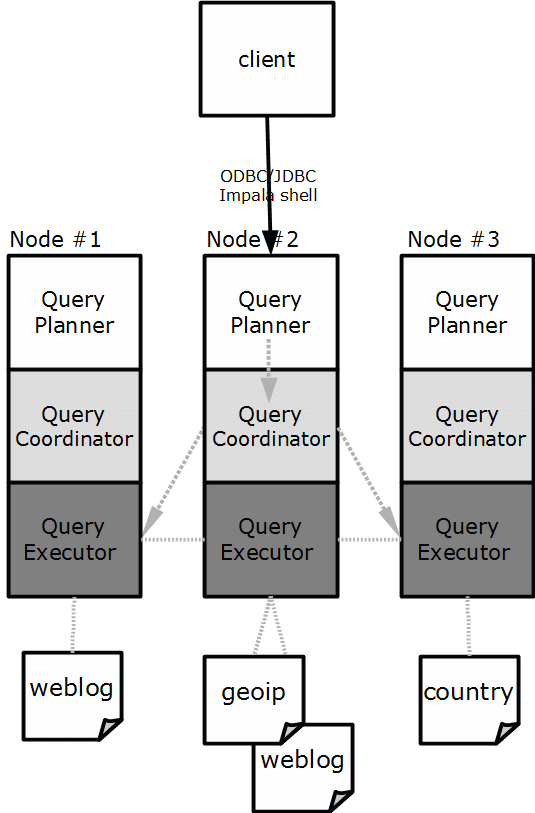 Figure 2 The three layers of the Impala daemon
Figure 2 The three layers of the Impala daemon
- Top layer: Query Planner accepts and validates the SQL queries, transforms them into a mathematical plan and finally compiles the plan into a distributed query plan made up of fragments, which it hands over to the Query Coordinators.
- Second layer: Query Coordinator distributes the fragments and coordinates their execution amongst the nodes in the cluster. The component collects all the results and sends the answer back to the client.
- Third layer: Query Executor actually executes a fragment of the query and collaborates with other Query Executors. For example, a fragment scans the local data of the weblog table and filters the valid web logs. This fragment is send to all the nodes that contain a part of the weblog table. In Figure 2, the fragment that scans the weblog table will be executed on node 1 and node 2.
Let’s begin exploring the details of the Impala Daemon, by looking at its first layer: the Query Planner.
###1.1 Query Planner In this section we will go through the three steps of the Query Planner’s process of accepting and validating SQL queries, and then handing them over to the Query Coordinators:
- Parsing the textual representation of the query into a logical plan,
- Optimizing that plan for execution, and finally
- Dividing the plan into fragments to be run in parallel on different nodes in the cluster.
####1.1.1 Parsing queries into logical plans
The query planner starts to parse the textual representation of the query in a logical plan. The logical plan is a number of consecutive steps needed to execute the query and is represented by a tree, where each node in the tree performs a single simple operation, as shown in Figure 7.3 below. The query planner starts to parse the textual representation of the query in a logical plan. The logical plan is a number of consecutive steps needed to execute the query and is represented by a tree, where each node in the tree performs a single simple operation, as shown in Figure 3 below.
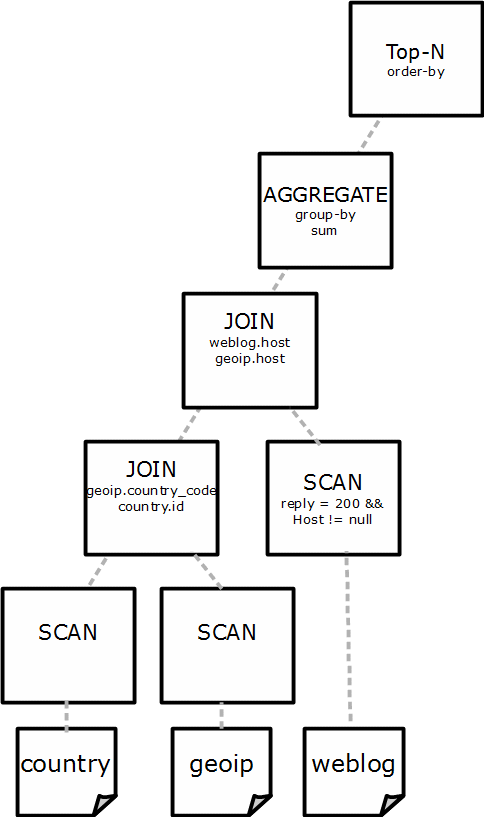 Figure 3 Logical Plan of the SQL query
Figure 3 Logical Plan of the SQL query
As you can see in the figure, when querying data from the Nasa dataset, data flows from the bottom of the tree to the top. Each node processes the incoming data and pushes the results further up the tree. At the bottom of the tree, the nodes will scan the tables, while the top node contains the final results of the query. Each node executes a single operation, also known as a plan operator. The most relevant plan operators are (working from the bottom of the figure up):
- Scan: The leaves of the tree contain the scan nodes. These nodes scan the table and apply the predicates, such as WHERE filters. There is a scan node for each different type of data access: HDFS csv, HDFS Parquet, HBase, …
- Aggregate: These nodes represent the aggregate functions, such as GROUP-BY and SUM.
- Top-N: As the name indicates, this node sorts the results and keeps only the first N results.
- Join: As discussed in Chapter 5, a join operator finds the matching rows in the right hand table for every row in the left hand table. Several algorithms exist to implement a join operator: nested loop, sort-merge and hash-join are the best known. Once the Query Planner has finished the transformation of the query into a logical plan, it proceeds with its second step: Optimizing that plan.
###1.1.2 Optimizing the query plan
SQL is a declarative language, which means you specify what you want, but you don’t specify how it should be calculated. As a consequence, there are different logical plans possible for the same query. The task of the optimizer is to select the most efficient plan. But there is a trade-off between the time spent selecting the best plan and the quality of the plan. Within the time limitations of a real-time SQL engine, the optimizer cannot afford to build every possible logical plan. At one point, it will select a plan, but there is no guarantee the optimizer selects the best possible plan.
Any optimizer modifies the logical tree without changing the query result. These modifications are based on algebraic laws that guarantee the same outcome. The best plan for a client is the plan that delivers the results as fast as possible. To achieve this, the optimizer will aim to process as little data as possible and applies two techniques: early elimination and join optimization.
EARLY ELIMINATION: REMOVING ROWS FROM THE LOGIC TREE
The first technique, early elimination, consists of removing as many rows as possible at the bottom of the logical tree. This is realized by pushing filters (WHERE clauses) down to the bottom of the tree. The more rows the scan nodes can eliminate, the fewer rows will end up higher in the tree.
This row elimination is illustrated in Listing 4, which shows an extract of the EXPLAIN command, which we’ll discuss in more detail in section 2 , when we discuss performance profiling. For the moment, it’s enough to recognize that the optimizer added the predicate geoip.host IS NOT NULL in the Scan node.
Listing 4 Early Elimination with EXPLAIN command
EXPLAIN <our query>
…
01:SCAN HDFS [nasa.geoip]
| partitions=1/1 size=352B
| predicates: weblog.geoip.host IS NOT NULL #A
00:SCAN HDFS [nasa.weblog]
partitions=1/1 size=149.56MB
predicates: weblog.host IS NOT NULL, weblog.replycode = 200
#A The optimizer added this predicate
In our query, we specified that weblog.host = to geoip.host, and we also specified that weblog.host is not null. Based on these predicates, the optimizer is able to deduce that the geoip.host is not null, and the optimizer will add this new predicate to the logical plan.
The result is not modified, but it can possibly eliminate a number of rows from the geoip table during the initial scan process. The effect is that less data will be exchanged over the network and less data needs to be processed.
JOIN OPTIMIZATION: GETTING JOINS IN THE RIGHT ORDER
Once the early elimination strategy is applied, the optimizer continues with the second and most crucial task: getting the JOIN operations in the right order. Algebraic laws tell us that inner joins are commutative and associative, meaning the order of the tables does not have an impact on the end result. However, the order does have a huge influence on processing time.
As discussed in chapter 5, a join operation matches each row of the first table with each row of the second table. In most cases, the matching is done by keeping one table completely in memory, and by scanning the second table row by row. During the scan, each scanned row is matched against each row of the in-memory table. It’s obvious to keep the smallest table in memory and scan the largest table. A left-deep tree strategy, as implemented by Impala, keeps the right-hand table in memory and scans the left-hand table. The name left-deep tree comes from the resulting tree, which has a long left side branch with small branches on the right, as you originally saw in Figure 3, repeated here for clarity.
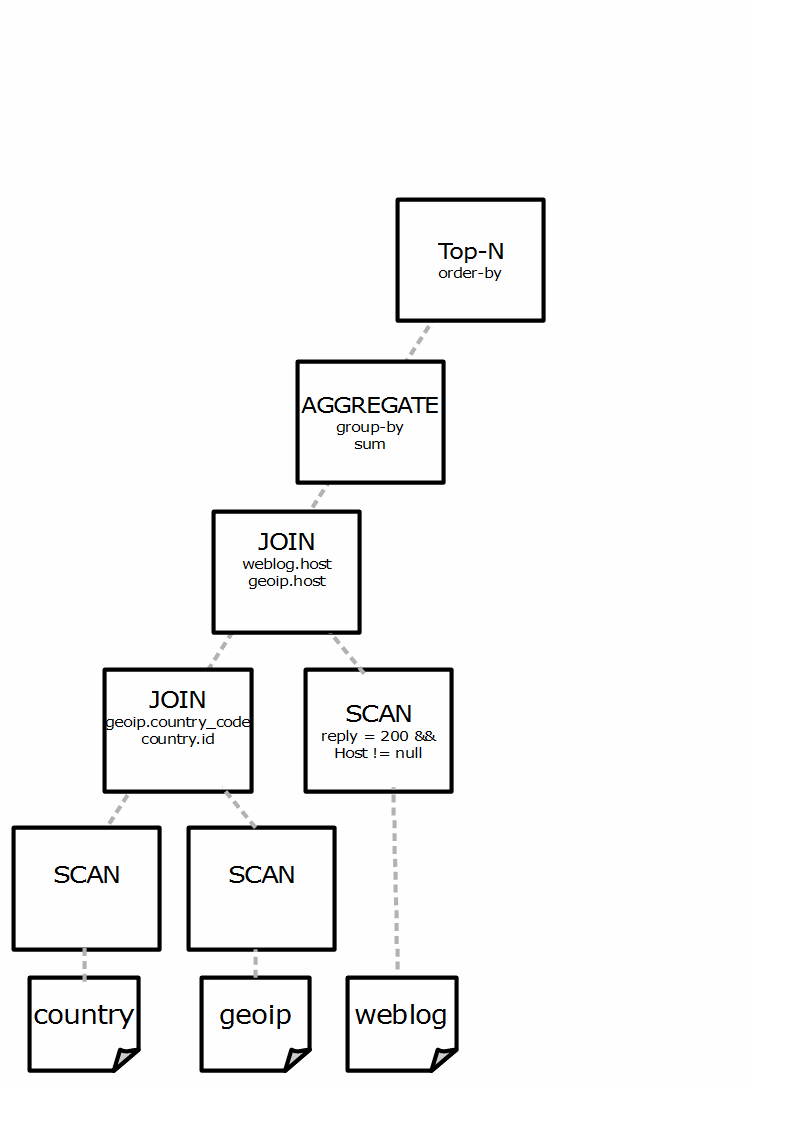 Figure 4 Impala’s left-deep tree strategy results in logical plans with long branches on the left side
Figure 4 Impala’s left-deep tree strategy results in logical plans with long branches on the left side
Left-deep tree in Impala’s distributed environment In Impala’s distributed environment, it’s crucial to avoid data exchange over the network as much as possible. This can be achieved by putting the largest table at the left-hand side and the smaller table at the right-hand.
In the context of HDFS, the left-hand data is never large, since only the local HDFS blocks of the table is scanned. It is important to recognize that the right-hand table is not local and must be exchanged over the network. Therefore, the smallest table should appear at the right- hand of the join operator.
HASH-JOIN ALGORITHM
In most cases, Impala uses the hash-join algorithm to join the 2 tables. This algorithm starts with building a hash table of all the rows of the right-hand table. The hash function uses the join columns as hash value. Once the hash table is completed, the left-hand table is scanned. Each row in that table is hashed on the join columns and each hash value points to the relevant rows in the hash table.
As you can see in the next listing, the algorithm is relatively simple to implement, but requires the hash table to fit in memory. A bigger constraint of the hash-join algorithm is that it only supports equijoin predicates. An equijoin is the equality test between the join columns, and this constraint is due to hash values only being comparable on equality.
The next listing explains in pseudo code how the hash-join algorithm is implemented.
Listing 5 Pseudo code of hash-join algorithm
// country inner join geoip on geoip.country_code = country.code
//phase 1: Build phase
for each row in country table #A
hash-value = hash(country.code)
map[hash-value].add(row) #A
//phase 2: Probe phase
row = read row from geoip table #B
while row
hash-value = hash(geoip.country_code)
if map[hash-value] != null #C
//found matching row, send both rows to output stream
else
//do nothing
row = read next row from country table #D
#A: Build phase stores the right-hand table in memory
#B: The left-hand table is scanned row by row.
#C: Each row is matched against the in-memory table
#D: map data structures only support equality on the keys.
Non-equijoin predicates
Since version v1.2.2, Impala support non-equijoin predicates, but only on a CROSS JOIN operator. A cross join is implemented as a nested loop over both tables. As explained in Chapter 5, a cross join can be very expensive as it combines every row from the left-hand with every row from the right-hand input. It should only be applied on small tables. The join predicate is specified in a WHERE clause.
OPTIMAL JOIN ORDER
Impala’s optimal join order is to have the largest table at the left side, joined with the smallest table. This order keeps the intermediate results as small as possible.
The first table is read locally and the second and additional tables in the join operation are sent over the network and will impact the performance. This first join will result in a small intermediate result. Then, as tables are added in increasing size to the join operation, the intermediate results set can be kept small. Using that information, our query should be rewritten as Listing 7.6.
Listing 6 Impala’s optimal join order
SELECT country.name, SUM(weblog.bytes) as total
FROM weblog #A
INNER JOIN geoip ON geoip.host = weblog.host #B
INNER JOIN country ON country.id = geoip.country_id
WHERE weblog.reply = "200" and weblog.host is not null
GROUP BY country.name
ORDER BY total
LIMIT 10
#A left-hand table is largest
#B additional tables in increasing size.
Since the tables in the join operation can refer to intermediate results, sub-queries or views, the size of these data sets is unpredictable. In other words, the optimizer is unable to know the size of the data set. Although the weblog table is the largest table in our query, this is maybe no longer the case when a filter, such as replycode != 200 is applied to the table. To overcome this problem, you can either guide yourself the optimizer by using hints, or you can compute the statistics on the table.
If no statistics are available, the optimizer does not change the order of the tables, and it is up to you to figure out the optimal join order. As mentioned before, since Impala uses a left-deep tree, the largest table should be placed at the left hand side of the join, followed by increasingly larger tables, as demonstrated in Listing 6.
Recent versions of Impala (version 1.2.2 and newer) come with a Cost-Based Optimizer (CBO). A CBO estimates the cost of each plan, and will select the plan with the lowest cost. The cost is based on statistics of the table and the columns. Currently, Impala does not automatically maintain the statistics for the CBO; it’s up to you to compute the statistics, as shown in Listing 7.7 below. Note that future releases will support automatic as well as incremental statistics.
Listing 7 Enable the statistics on a table
[localhost.domain:21000] > COMPUTE STATS weblog;
[localhost.domain:21000] > COMPUTE STATS geoip;
[localhost.domain:21000] > COMPUTE STATS country;
This command can take some time depending on the size of the table. It gathers several statistics to support the CBO: - Table statistics contain the cardinality of the table, the number of files and the type of file for each partition. - Column statistics contain a number of statistics. The most important one is the number of distinct values for each column. This allows to roughly estimate the impact of a single filter on a column. The statistics can be checked up by issuing the commands shown in Listing 8 below.
Listing 8 Verify the statistics for a table
[localhost.domain:21000] > SHOW TABLE STATS weblog; #A
Query: show TABLE STATS weblog
+---------+--------+----------+--------------+--------+
| #Rows | #Files | Size | Bytes Cached | Format |
+---------+--------+----------+--------------+--------+
| 1891715 | 1 | 174.07MB | NOT CACHED | TEXT |
+---------+--------+----------+--------------+--------+
[localhost.domain:21000] > SHOW COLUMN STATS weblog; #B
Query: show COLUMN STATS weblog
+--------+-----------+-----------+--------+----------+-------------------+
| Column | Type | #Distinct | #Nulls | Max Size | Avg Size |
+--------+-----------+-----------+--------+----------+-------------------+
| host | STRING | 82930 | -1 | 53 | 18.48950004577637 |
| dt | TIMESTAMP | 0 | -1 | 16 | 16 |
| query | STRING | 21905 | -1 | 333 | 44.18450164794922 |
| reply | INT | 5 | -1 | 4 | 4 |
| bytes | INT | 14065 | -1 | 4 | 4 |
+--------+-----------+-----------+--------+----------+-------------------+
In the performance profiling section (section 2) later in the chapter,you’ll see the importance of the statistics on your query. If despite the statistics, Impala makes the wrong assumptions, you can override the optimizer using the keyword STRAIGHT_JOIN. When using this hint, the optimizer will not change the order of the tables in the join operation.
The next query shows how to bypass the optimizer. The example forces the smallest table at the left-hand side, which is the worst-case scenario for Impala.
Listing 9 Worst case scenario using STRAIGHT_JOIN
[localhost.domain:21000] > SELECT STRAIGHT_JOIN countries.name, SUM(weblog.bytes) as total #A
FROM countries
INNER JOIN geoip ON geoip.country_code = countries.code
INNER JOIN weblog ON weblog.host = geoip.host
WHERE geoip.host IS NOT NULL AND weblog.reply = 200
GROUP BY countries.name ORDER BY total DESC LIMIT 10;
#A use STRAIGHT_JOIN hint immediately after the SELECT statement
What we have been discussing is the transformation of the query and the optimization of the logical plan as it would be executed on a single node. The single node plan also needs to be partitioned into fragments so that the plan can be distributed over the cluster; this is the final step of the Query Planner.
###1.1.3 Distributing the Optimized Plan Fragments
The final task of the Query Planner is to partition the optimized plan into plan fragments. As Figure 5 shows, each plan fragment is distributed to one or more nodes in the cluster.
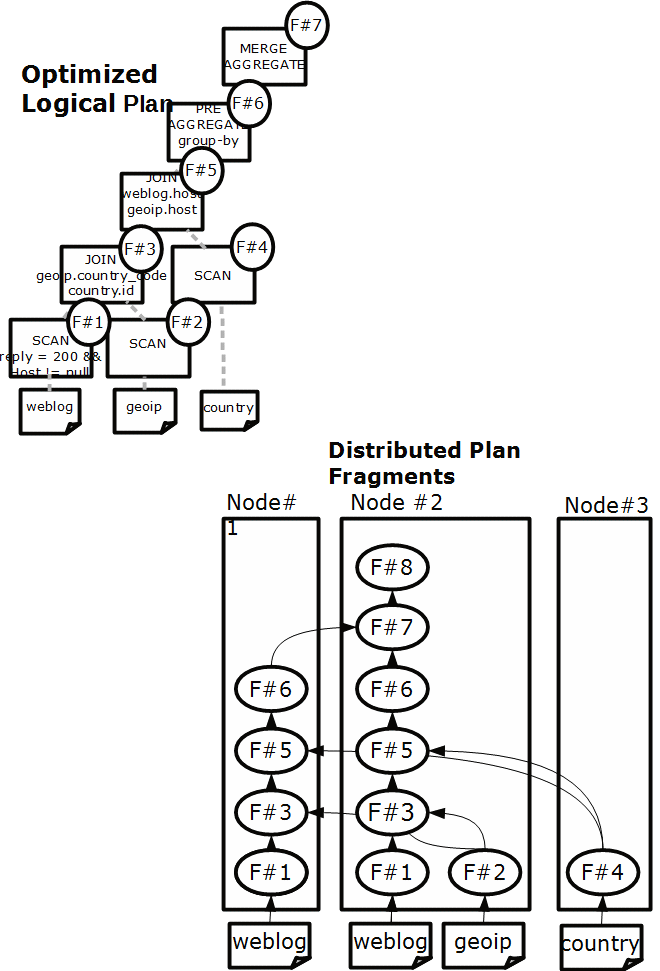 Figure 5 View of the distributed plan fragments.
Figure 5 View of the distributed plan fragments.
On the left side of the figure, you can see the optimized logical plan. Each node is annotated with a fragment number (F#). At the right side of the figure, you see the physical distribution of each fragment. For example, the fragment F#1 (that scans the weblog table) is deployed on node 1 and node 2, while the fragment F#4 (that scans the country table) is deployed only on node 4.
The goal of the fragmentation is to minimize the overall data transfer between the nodes by maximizing the data locality. Each plan operator is converted into its distributed version:
- Scan: The scan fragments (shown at the bottom left of the figure, F#1, F#2 and F#4) are sent to the relevant data nodes to scan the local HDFS or HBase blocks of the file. The predicates will filter out as much rows as possible to minimize the intermediate results. The Scan nodes communicate with the Impala disk manager to read the HDFS blocks directly from disk, bypassing the DataNode RPC layer. If your query involves an HBase table, each node performs a HBase scan on the key range that the node hosts.
- Hash-Aggregation: Each aggregation is decomposed in 2 parts. The first one, the pre-aggregate, is run on each node and aggregates only the local data. The result of each pre-aggregation is send to a single node where the second part, the merge-aggregate takes places. Coming back to the example, several nodes will perform the group-by operation, followed by the operation sum(weblog.bytes) (fragment F#6 in the figure). Each subtotal is sent to the merge-aggregate (fragment F#7), which will calculate the sum of the subtotals (sum(sum(weblog.bytes)).
- Top-N: Similar to the Hash-Aggregate, the sort is decomposed in a pre Top-N which runs on several nodes in parallel and one merge Top-N, which sorts the pre-sorted sub parts.
- Exchange: The nodes that participate in a JOIN operator need to exchange data. Depending on the estimated size of each of the participating tables, Impala chooses between two different exchange strategies:
- broadcast join: this strategy is the default strategy and is used when the right hand table is small enough to be send completely to each other participating node.
- partitioned join: (not to be confused with a partitioned table). This strategy is used when both tables are large and have more or less the same size. Each table is hash-partitioned on the join columns and the parts are sent to appropriate nodes. The choice is based on the estimated data movement between the nodes, which are based on the table statistics.
Overriding the Optimizer
Similar to the STRAIGH_JOINT hint, it’s possible to override the optimizer to use a specific exchange strategy. The broadcast hint forces the right-hand table to be broadcasted to every participating node, the shuffle hint forces the partitioned join. As mentioned before, these hints should only be used when the optimizer makes the wrong assumptions (which happen less and less with the cost based optimizer).
Listing 10 is an extract of the EXPLAIN command (more details in section 7.4) that demonstrates that the country table is broadcasted to all participating nodes in the cluster.
Listing 10 BROADCAST hint
[localhost.domain:21000] > EXPLAIN SELECT countries.name, …
…
| 03:HASH JOIN [INNER JOIN, BROADCAST] #A
| | hash predicates: geoip.country_code = countries.code
| |
| |--07:EXCHANGE [BROADCAST] #B
| | |
| | 00:SCAN HDFS [nasa.countries]
| | partitions=1/1 size=1.01KB
#A Broadcast join is Impala’s name for a hash-join
#B The exchange uses the broadcast strategy, sending all the rows to all nodes
Once the Query Planner has finished transforming, optimizing and fragmenting the plan, it hands the fragments over to the second layer of the Impala daemon, the Query Coordinator.
The Query Coordinator distributes the fragments based on the node availability and the data locality. The availability of each node is given by the Statestore service and the information concerning the data locality comes from the HDFS Name Node. Once the fragments are distributed, the Query Coordination starts the execution on the remote Impala daemons. If a single fragment fails, the coordinator will cancel the complete query and send an error to the client . It is the Query Coordinator that sends the final results of the query back to the client. If the query does not include a final aggregation, the query coordinator can stream in the incoming results directly to the client. If the query contains a final aggregation, such as Top-N, the Query Coordinator will execute the last plan fragment before sending the final result to the client.
The third layer of the Impala daemon, the Query Executor executes a single plan fragment. The execution of a fragment processes data, such as scanning the local data or pre-aggregating a large data set. Plan fragments process billions of rows for a single query; it’s crucial that these operations are optimized for speed. Every single optimization in the Query Executor (even as small as a few CPU cycles) adds up quickly when processing billions of rows.
A very common operation in the Scan node is to read a comma separated file and to split each line into columns. To split the line by comma, each individual character must be compared to the comma character. As we will shortly see, Impala uses several techniques to make that splitting extremely fast.
The fascinating aspect of Impala’s Query Executor is that it demonstrates how low-level optimizations play a role in the world of Big Data. The most important tools and techniques used in the Query Executor to improve the performance of the plan fragments are:
- C++ to avoid any overhead
- Data Alignment for a smoother CPU pipeline
- Code generation at run-time, in contrast with traditional interpretive methods.
The Query Planner is written in Java, for easier integration of Hadoop eco-system, but the Query Executor is fully written in C++. There is no point in discussing the virtues of Java versus C++, there are already enough flame wars on that topic. For Impala’s requirement, C++ does have some advantages.
- Deterministic Memory Management: C++ offers complete control over when the memory is released whereas the Java garbage collector can kick in at unexpected moments, consuming CPU cycles which can be better used elsewhere.
- Template meta-programming: In contrast to Java, C++ provides template meta programming. This advanced technique performs optimizations during compile time; some operations (such as loop unrolling or static polymorphism) are done only once during compilations, instead of every single execution.
- No Bound-Check: One of the motivations to create Java was to build a safer C/C++. With Bound-Check, Java introduced a technique that checks the boundaries of a variable. The best known example is checking if an index of an array is within its boundaries. Although the bound-check avoids buffer overflows and segmentation exceptions during execution, it comes at a performance price. C/C++ does not have this automatic check to increase the speed.
- LLVM: Since the code is written in C++, Impala can take advantage of a set of compiler tools to improve performances. We will discuss some of these tools in a separate section. Although writing correct C++ code is a bigger challenge, the end result is more tuned to the specific problem: write low-level code to get the most out of the processor.
DATA ALIGNMENT
Data alignment is the way the data is organized in memory. When the data is organized according the CPU’s characteristics, the data can be accessed faster. Faster access results in faster execution of the query.
Processors access memory in chucks. For example, on a 64-bit processor, the chunk size is 8 bytes (which is 64 bits). The processor reads data from memory at offsets that are a multiple of 8. If an application needs data that is located at offset 14, the CPU will read the chunk at offset 8 and do some arithmetic to extract the requested data. To avoid this inefficient access, it is possible to align each data record at the start of a chunk. This practice, also known as padding, is less efficient in memory size, since it inserts empty spaces. Instead of locating the data record at offset 14, it will be moved to offset 16 and the location 14 and 15 will remain empty. The advantage is that the processor can access the requested data without any additional extraction arithmetic. Aligned data looks like LEGO blocks ranged on a single line, as shown in the figure below, compared to the blocks packed in a square.
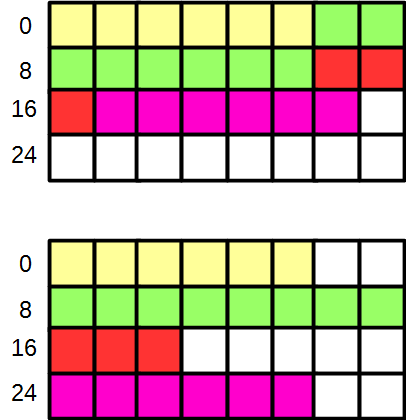 Figure 5 Data Alignment: top figure shows packed data, bottom figure shows aligned data
Figure 5 Data Alignment: top figure shows packed data, bottom figure shows aligned data
SIMD INSTRUCTIONS
Another optimization used in Impala is exploiting some specialized instructions on modern processors, especially the SIMD instructions. These “Single Instruction, Multiple Data” functions allow to execute a single operation (such as comparison or multiplication) on multiple data records simultaneous. As the data is processed in parallel, it gives the applications a performance boost. Impala’s text parsing uses these specialized functions to improve performance. The text parsing is probably one of the most often called functions in Impala. Every single row from a csv file needs to be split into the different columns; these columns are separated by a specific character, such as a comma. The parser needs to find the positions of each separator.
One of the many SIMD instructions allow comparing a number of characters in parallel. The resulting bit mask contains for each input character a “1” if the characters match and a “0” if the characters are different. The listing below is a conceptual illustration of how the first line of the weblog table is parsed using the SIMD instructions. The result contains a “1” where a comma is found. This operation is done in parallel on all characters in the input operand.
Listing 11 Illustration SIMD for text parsing
operand 1 = “192.168.1.1, 200, [“
operand 2 = “,”
result = “0000000000010000100” #A
#A 2 bits are set where the character matches the comma
The SIMD instruction gains a couple of clock cycles per operation, but taking into account that this gain is repeated over a billion or more rows, the final performance boost can be impressive.
CODE GENERATION
The facts of a query, such as the type of the column or an arithmetic operation, are not known at compile time. Therefore a lot of databases rely on an interpretive approach. This approach typically uses a large switch over the facts to execute the query. These switches are far from optimal for modern CPU hardware. Taking branches (if-then-else) are cheap for a CPU, but only if the branch prediction is correct. A switch statement over a query fact ruins that prediction, since the facts in a random SQL query cannot be predicted.
Imagine we need the smallest weblog reply in the database, as shown in Listing 7.12. Listing 12 Smallest weblog reply
SELECT MIN(weblog.bytes) FROM ... /* weblog.bytes is defined as INT */
The type of that column is not known at compile time. So, at run-time, a traditional SQL engine will switch over all possible types of columns, as indicated in listing 7.13, thereby losing all advantages of modern CPU pipelining. Listing 13 Interpretive approach
switch (table->column->type) {
case INTEGER: return min(arg1, arg2); #A
case FLOAT: return fmin(arg1,arg2); #B
case DOUBLE: ...
...
}
#A if type of column is INTEGER, use min function
#B if type of column is FLOAT, use fmin function
Impala generates code on-the-fly that includes that run-time information and applies Just-In-Time (JIT) compilation to execute the generated code. The generated code is as efficient as handwritten assembly code. The next listing code shows the assembler-like code that is generated at run-time for this particular MIN(weblog.bytes) operation. It takes into account that the type of the weblog.bytes column is a 32-bit integer. This generated function is compiled and executed instantaneous. Listing 7.14 Impala – LLVM generated code
i32 @fn(i32 %1, i32 %2) { #A
%0 = icmp slt i32 %v1, %v2 #B
br i1 %0, label %ret-v1, label %ret-v2 #C
ret-v1: ret i32 %v1
ret-v2: ret i32 %v2
}
#A generate a MIN function for Integer types
#B compare the first and second argument
#C branch accordingly
As mentioned earlier, shaving off a couple of CPU cycles for a single operation ends up having a huge impact on the performance when processing large volumes of data. Impala uses locally generated functions tuned for the specific query instead of a slower interpretive approach. For testing purposes, the code generation can be turned off by using the command, as shown below. Listing 15 Impact of code generation
[localhost.domain:21000] > SELECT countries.name…
…
Returned 10 row(s) in 40.31s #A
[localhost.domain:21000] > SET DISABLE_CODEGEN=1;
[localhost.domain:21000] > SELECT countries.name…
…
Returned 10 row(s) in 55.53s #A
#A In this particular example, the code generation saved almost 30%
LLVM: OPEN-SOURCE COMPILER TOOLKIT FOR OPTIMIZATIONS
A lot of Impala’s optimizations are made possible thanks to an open-source compiler toolkit called LLVM (Low-Level Virtual Machine). The Query Executor uses LLVM components to generate and optimize code during run-time. The generated code is tailored made for the specific local hardware of the node on which the Query Executor is running. Central to the LLVM toolkit is the assembler-like language, called LLVM IR (Intermediate Representation, as shown in Listing 13). LLVM IR is a typed low-level instruction set, very similar to Java byte code. The compiler tool is implemented in 3 phases, as shown in Figure 6 below:
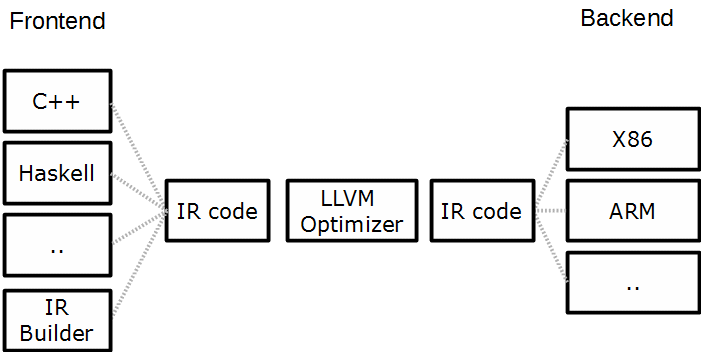 Figure 6 The three phases of the Low-Level Virtual Machine work together optimize Impala’s performance
Figure 6 The three phases of the Low-Level Virtual Machine work together optimize Impala’s performance
As you can see in the figure above, the Low-Level Virtual Machine includes:
- A frontend (left side of the figure) parses the input code and translates it into LLVM IR.
- The LLVM optimizer (center) reads LLVM IR, improves the code and writes LLVM IR.
- A backend (right side of the figure) generates machine code for a specific environment.
When the Query Executor receives a plan fragment, it will construct LLVM IR code on-the-fly for some fragments, for example for the MIN function. The IR code is then optimized and compiled for the specific hardware. LLVM JIT shares a lot of the advantages with Java JIT, such as removal of function calls and branches and unrolling loops. Many optimizations mentioned in this section, like data alignment and applying intrinsic CPU features such as SIMD operations, are possible thanks to LLVM.
A lot of work in Impala is done to ensure very fast response times. Early optimization and JOIN reordering will minimize the data transfers; plan fragments make that the query can be executed in parallel over several nodes in the cluster and finally, the Query Executor will apply low-level techniques, such as data alignment and JIT code generator to exploit every possible hardware feature.
Now that we have a better understanding of a query’s pipeline, let’s use built-in commands that illustrate the execution plan and low-level details of the execution, and allow us to get an overview of query bottlenecks.
A performance profile is created by a number of tools that give a comprehensive overview of how the query is executed and where the bottlenecks are.
You can use the output of these tools to determine if the query will be executed efficiently. Impala offers 3 different tools to analyze the queries:
- EXPLAIN, which returns the plan fragments without actually executing the query.
- SUMMARY , which gives a high level overview of the run time statistics
- PROFILE, which gives a exhaustive listing of the run time statistics
All three of these tools are run after the execution of the query, and give run-time statistics, such as the number of processed rows or the amount of consumed memory.
###2.1 EXPLAIN
First, we simply execute the query as it is (shown in Listing 16), and then use the results of the EXPLAIN to tune the query, as shown in Listing 7.17.
Listing 16 Executing the query
[localhost.domain:21000] > SELECT country.name, SUM(weblog.bytes) as total FROM country INNER JOIN …
+----------------+---------------+
| name | total |
+----------------+---------------+
| United States | 1002748912380 |
| United Kingdom | 421032437956 |
| Canada | 89049419429 |
| Australia | 43668928732 |
| Germany | 30698423746 |
| Japan | 27716818088 |
| Sweden | 15354623998 |
| Netherlands | 7978280412 |
| Italy | 7683163070 |
| Finland | 6913686014 |
+----------------+---------------+
Returned 10 row(s) in 29.79s
The result of the EXPLAIN command is shown in the next listing.
Listing 17 EXPLAIN of our running query
[localhost.domain:21000] > EXPLAIN SELECT country.name, SUM(weblog.bytes) as total FROM country INNER JOIN …
Query: explain SELECT country.name, SUM(weblog.bytes) as total FROM country INNER JOIN geoip ON geoip.country_code … DESC LIMIT 10
+--------------------------------------------------------------------------
| Explain String
+--------------------------------------------------------------------------
| Estimated Per-Host Requirements: Memory=4.23GB VCores=1 |
| WARNING: The following tables are missing relevant table and/or column | statistics. nasa.country, nasa.geoip, nasa.weblog |
| 11:MERGING-EXCHANGE [UNPARTITIONED] #A
| | order by: sum(weblog.bytes) DESC limit: 10
|
| 06:TOP-N [LIMIT=10]
| | order by: sum(weblog.bytes) DESC
|
| 10:AGGREGATE [MERGE FINALIZE]
| | output: sum(sum(weblog.bytes)) group by: country.name
|
| 09:EXCHANGE [HASH(country.name)]
|
| 05:AGGREGATE
| | output: sum(weblog.bytes) group by: country.name
|
| 04:HASH JOIN [INNER JOIN, BROADCAST]
| | hash predicates: geoip.host = weblog.host #B
| |
| |--08:EXCHANGE [BROADCAST] #C
| | |
| | 02:SCAN HDFS [nasa.weblog] #D
| | partitions=1/1 size=174.07MB
| | predicates: nasa.weblog.host IS NOT NULL, weblog.reply = 200
|
| 03:HASH JOIN [INNER JOIN, BROADCAST]
| | hash predicates: country.code = geoip.country_code
|
| |--07:EXCHANGE [BROADCAST] #C
| | |
| | 01:SCAN HDFS [nasa.geoip] #D
| | partitions=1/1 size=16.46MB
| | predicates: geoip.host IS NOT NULL
|
| 00:SCAN HDFS [nasa.country] #D
| partitions=1/1 size=1.01KB
+--------------------------------------------------------------------------
#A Each fragment has a numbered label which you can see at the beginning of the line (#A is 11)
#B Early elimination
#C The tables geoip and weblog are broadcasted to the participating nodes
#D The SCAN nodes at the bottom of the logical plan, with the predicates
The output is the tree of plan fragments and is mostly used to get an idea how the query will be executed by Impala. You enter the EXPLAIN command in the Impala shell, followed by the query you want to investigate. With a bit of imagination, you can visualize the tree of plan fragments in the EXPLAIN output. Each plan fragment is labelled with a number (00,01,..) at the beginning of the line. The HDFS scan nodes (00,01,02 ) are located at the bottom of the tree, the final merging-aggregate node (11) sorts the intermediate aggregates and produces the final result.
As explained earlier, the optimizer applies the ‘eliminate early’ strategy and adds the predicate nasa.weblog.host IS NOT NULL in the scan node 02 (Annotation #C). However, the join sequence is far from optimal. The reason is that the optimizer does not have any knowledge of the size of the tables and therefore cannot select the largest table. These statistics will be automatically computed in future versions of Impala, but for the moment, you need to apply the command COMPUTE STAT <table>, as the listing below shows.
Listing 18 Compute the statistics
[localhost.domain:21000] > COMPUTE STATS weblog;
Query: compute stats weblog
+-----------------------------------------+
| summary |
+-----------------------------------------+
| Updated 1 partition(s) and 5 column(s). |
+-----------------------------------------+
[localhost.domain:21000] > COMPUTE STATS geoip;
..
[localhost.domain:21000] > COMPUTE STATS country;
..
We rerun the EXPLAIN command. The output in listing 7.19 is reduced to contain only the relevant parts of the plan fragment tree.
Listing 19 Explain of our query, with statistics
[localhost.domain:21000] > EXPLAIN SELECT country.name, SUM(weblog.bytes) as total
FROM country INNER JOIN …
Query: explain SELECT country.name, SUM(weblog.bytes) as total
FROM country INNER JOIN geoip ON geoip.country_code … DESC LIMIT 10
…
| | |
| 04:HASH JOIN [INNER JOIN, BROADCAST] |
| | hash predicates: geoip.host = weblog.host |
| | |
| |--08:EXCHANGE [BROADCAST] |
| | | |
| | 02:SCAN HDFS [nasa.weblog] |
| | partitions=1/1 size=174.07MB |
| | predicates: nasa.weblog.host IS NOT NULL, weblog.reply = 200 |
| | |
| 03:HASH JOIN [INNER JOIN, BROADCAST] |
| | hash predicates: geoip.country_code = country.code |
| | |
| |--07:EXCHANGE [BROADCAST] |
| | | |
| | 00:SCAN HDFS [nasa.country] #A |
| | partitions=1/1 size=1.01KB |
| | |
| 01:SCAN HDFS [nasa.geoip] #B |
| partitions=1/1 size=16.46MB |
| predicates: geoip.host IS NOT NULL |
+--------------------------------------------------------------------+
#A The optimizer puts the country table at the right-hand
#B The optimizer puts the geoip table at the left-hand
You notice that the optimizer changed the order of the JOIN operation. It might come as a surprise that the optimizer puts the geoip table at the left-hand side, and not the weblog table. As mentioned before, the optimizer includes the column statistics to estimate the size of the dataset. But the optimizer will not simply use the total number of rows but it will take the number of distinct values per column into account. The optimizer is tuned for a common case where the join operation contains a selective WHERE clause. The selective clause is a filter that selects a single distinct value, such as WHERE reply = 200. This means that each row in the left-hand table will join only the rows from the right-hand table with a selective value and will not join every single row of the right-hand table.
Looking at the column statistic of our example (listing 7.19), the weblog table has 1.8M rows and the host column has 82930 distinct values. This gives an average of 1.8M/828930 rows per distinct value. The geoip table has 365K rows and the host column has 22306 distinct values, meaning 365K/22306 rows per distinct value on average. The optimizer compares the two different join orders and will choice the one with the smallest output:
- weblog INNER JOIN geoip gives 1.8M lines joined with (365K/22306) lines which results in = 31 031 692 lines.
- geoip INNER JOIN weblog gives 365K lines join with (1.8M/82930) lines which results in = 841 962 lines
The optimizer is tuned for the common case where a JOIN operation contains a selective WHERE clause. When you know that your query does not fit in that common case, it is worth forcing the optimizer not to change the order of the JOIN table by applying the STRAIGHT_JOIN hint (as seen in Listing 10 ).
###2.2 SUMMARY
SUMMARY OUTPUT FOR EXPLAIN
The EXPLAIN tool gives a global idea of how the SQL engine will execute the query by giving you the logical plan and the different fragments. This information is generated without actually running the query. For more detailed statistics, you can issue the SUMMARY statement immediately after running the query. For each fragment, the SUMMARY output details
- #Hosts: The number of hosts on which the plan fragment was executed
- Avg Time: The average time the plan fragment needed to complete its execution
- Max Time: The maximum time over the plan fragments
- #Rows: The number of rows the plan fragment actually processed
- Est. #Rows: The number of rows the optimizer estimated
- Peak Mem: Maximum memory usage for the given plan fragment
- Est. Peak Mem: Memory usage estimated by the optimizer
- Details: Detailed information of the plan fragment (for example name of table or type of JOIN operation)
As we learned in the previous section, the optimizer does an estimation based on common cases. In our example, the estimation of the size of the JOIN dataset is wrong and as a consequence, the optimizer did not put the tables in an optimal JOIN order. Such wrong assumptions appear clearly in the output of the SUMMARY tool.
The listing below focuses on the #Rows and #Est. Rows information for our query, more particular the SCAN HDFS plan fragment for the weblog table.
Listing 20 Detailed information for SCAN HDFS plan fragment for weblog table
[localhost.domain:21000] > SUMMARY;
+----------------+--------+---------+------------+--------------
| Operator | #Hosts | #Rows | Est. #Rows | Detail
+----------------+--------+---------+------------+--------------
| 11:MERGING-... | 1 | 10 | 10 | UNPARTITIONED
| 06:TOP-N | 1 | 10 | 10 |
| 10:AGGREGATE | 1 | 84 | 83 | MERGE FINALIZE
| 09:EXCHANGE | 1 | 87 | 83 | HASH(countries.na
| 05:AGGREGATE | 1 | 87 | 83 |
| 04:HASH JOIN | 1 | 67.28M | 1.67M | INNER JOIN, BROAD
| |--08:EXCHANGE | 1 | 1.70M | 378.34K | BROADCAST
| | 02:SCAN HDFS| 1 | 1.70M | 378.34K | nasa.weblog #A
| 03:HASH JOIN | 1 | 365.91K | 365.91K | INNER JOIN, BROAD
| |--07:EXCHANGE | 1 | 86 | 86 | BROADCAST
| | 00:SCAN HDFS| 1 | 86 | 86 | nasa.countries
| 01:SCAN HDFS | 1 | 365.91K | 365.91K | nasa.geoip
+----------------+--------+---------+------------+-----------------
#A The optimizer estimated reading 365K lines, but actual number is quite higher (1.7M)
The estimation by the optimizer is exactly 5 times less than the actual number of rows read. Again, the estimation is based on a common case that the WHERE predicates are selective: The column statistics in Listing 7.8 teach us that there are 5 distinctive values for the reply column. If the reply code would be equally distributed, the estimation for the filter “WHERE reply=200” would make sense.
###2.3 PROFILE
For even more detailed information, you can issue the PROFILE statement, immediately after the query execution. The output of this tool contains low-level information about memory, CPU, IO and network usage. The statistics are similar to debug level information and require good knowledge of the underlying source code. The following listing gives you an impression of the level of detail.
Listing 21 Impression of PROFILE output
Fragment F02:
Instance 1d44a4187d49caaf:50a7a2b30f3634a6 (host= localhost.domain:22000)
(Total: 5s062ms, non-child: 0ns, % non-child: 0.00%)
Hdfs split stats (<volume id>:<# splits>/<split lengths>): 0:2/174.03 MB
MemoryUsage(500.0ms): 12.00 KB, 32.05 MB, 24.05 MB, 24.05 MB, 24.02 MB, 24.02 MB, 24.02 MB, 24.05 MB, 16.05 MB, 24.05 MB, 24.05 MB
ThreadUsage(500.0ms): 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2
- AverageThreadTokens: 1.91
- PeakMemoryUsage: 32.12 MB (33677312)
- PrepareTime: 9.974ms
- RowsProduced: 1.70M (1701534)
- TotalCpuTime: 5s439ms
- TotalNetworkReceiveTime: 0ns
- TotalNetworkSendTime: 4.135ms
- TotalStorageWaitTime: 146.11ms
CodeGen:(Total: 487.914ms, non-child: 487.914ms, % non-child: 100.00%)
- CodegenTime: 9.947ms
- CompileTime: 397.601ms
- LoadTime: 84.472ms
- ModuleFileSize: 349.36 KB (357748) The output of the profile tools are also accessible via a web interface (port 25000).
The previous two sections discussed the largest service of Impala: the Impala daemon. The daemons are supported by two other services: the statestore and the catalog service, which we’ll explore next.
In constrast to the Impala daemon that runs on every node, there is only one instance of the statestore service. The goal of the service is to track the health of each individual Impala daemon and to distribute that information back to the cluster.
Each daemon registers to the statestore and subscribes to a number of topics. Topics are pieces of information that are required by the daemons to perform their tasks. Topics range from cluster membership to catalog updates. Each topic is annotated with a version, which guarantees that only the most recent information is kept.
The topic updates flow in both directions: daemons send regular updates to the statestore and the statestore dispatches that information to the subscribers of the topic. The regular updates from daemon to statestore also serve as a heartbeat. When a daemon fails to send a heartbeat during a certain period, the daemon is considered as dead and is excluded from the cluster. That information is dispatched so that other daemons avoid the dead cluster in future queries.
Because the daemons do not depend on that service for the query execution, the statestore is not a single point of failure. If when the statestore is down, the daemons will no longer receive up-to-date information, but continue processing queries with stale information. Once the statestore service comes back, the daemons will reconnect.
The service exposes a web interface (statestore node, port 25010) which displays detailed information such as the list of subscribers and the list of topics. This information is helpful for troubleshooting.
The third and final Impala service takes care of the metadata information about the data, such as organization in databases or layout of the tables. The catalog service centralizes any change in the metadata, passes these changes to the statestore, which then relays them to the daemons. Like the statestore service, there is only one instance of the catalog service. Since the statestore and catalog service communicate quite often, it is recommended to deploy them on the same node.
Any application of a CREATE|ALTER|DROP TABLE or CREATE|DROP DATABASE statement on a node will update the catalog service. Via the statestore service, the other daemons will be informed of the change. However, when the metadata is changed outside Impala, for example through Hive or by manipulating directly a HDFS file, you will need to issue the command REFRESH <table> or INVALIDATE METADATA on a node. The node will update the catalog service and the other daemons will receive an update. The REFRESH command causes the daemons to reload the new metadata as soon as they receive the update from the statestore. The INVALIDATE METADATA will only mark the metadata as stale on each daemon and only when the corresponding table is used in a query, will the metadata be refreshed.
This chapter explained the three different services that form Impala.
- Impala daemon, which plans, coordinates and executes a query
- The Query Planner transforms the textual form of the query into a logical plan, uses techniques such as early optimization and JOIN reordering to optimize the query and finally partitions the plan into fragments.
- The Query Coordinator coordinates the execution of the fragments, collects the intermediate data sets and streams the results back to the client
- The Query Executor processes the local data and is applies advanced optimization techniques such as data alignment and LLVM to boost performances.
- Statestore service, which collects and relays information to give the daemons a consistent view of the cluster
- Catalog service, which is responsible for collecting and distributing the clusters metadata.